
前言
在处理翻译项目时,我们会碰到各类问题,一旦碰到超大型的项目,那么问题就会被放大很多倍,工作变得十分复杂低效。以下是我们实践过程中总结的一些经验和教训。
背景
数千万字的大项目,文件特别多,文件夹套文件夹,而且有很多分散在不同文件夹下的同名文件。
第一步 整理要翻译的文件
我们首先用Project Console按原文件夹路径,整理出全部需要翻译的文件。
第二步 尝试创建Trados项目
项目很大,要先测试是否能成功创建Trados项目。实验证明项目过大,无法成功创建项目,提示内存不足。
这个错误在预料之中,因为Trados是32位程序,一旦项目文件太大,Trados就崩溃。碰到这种情况,我们只能将项目进行拆分,分拆成多个,分别创建Trados项目。Trados处理大型项目时,十分低效。在分别创建项目时,依然发现存在以下问题。
Trados在创建项目的第一步单单添加文件就需要耗费较长时间。
在创建项目过程中,Trados不会忽略有问题的文件,继续创建项目,而是直接告知你项目创建失败!然后你需要剔除有问题的文件,再重新创建项目。这样反复操作会耗费很长时间!
要剔除有问题的文件,可以在项目创建失败后,查看错误结果,记得将错误截图,找到对应的文件。要快速找到文件,我们可以使用Everything程序,指定搜索路径,搜索对应的文件,然后将这些文件提出来,另行处理。不要在项目文件夹中人工慢慢找文件,这个很耗费时间。Everything检索速度极快,能瞬间找到对应的文件
打开Everything,如下图所示,点选菜单栏上的搜索 – 匹配路径。
接着将文件所在路径复制到Everything搜索字段
在指定路径搜索,填上搜索路径+空格+关键字,以下为本例中的搜索方式。
C:\Users\ROG\Desktop\Big Project\Source 样本
我们可以在Everything搜索结果列表中,选中对应的文件,直接将它剪切出来。
要加快项目创建速度,可以在项目创建的最后一个步,自定义只用“转换为翻译格式”和“复制到目标语言”两个任务。若使用默认任务序列,后三个默认任务(见下图),执行过程也很耗费时间。
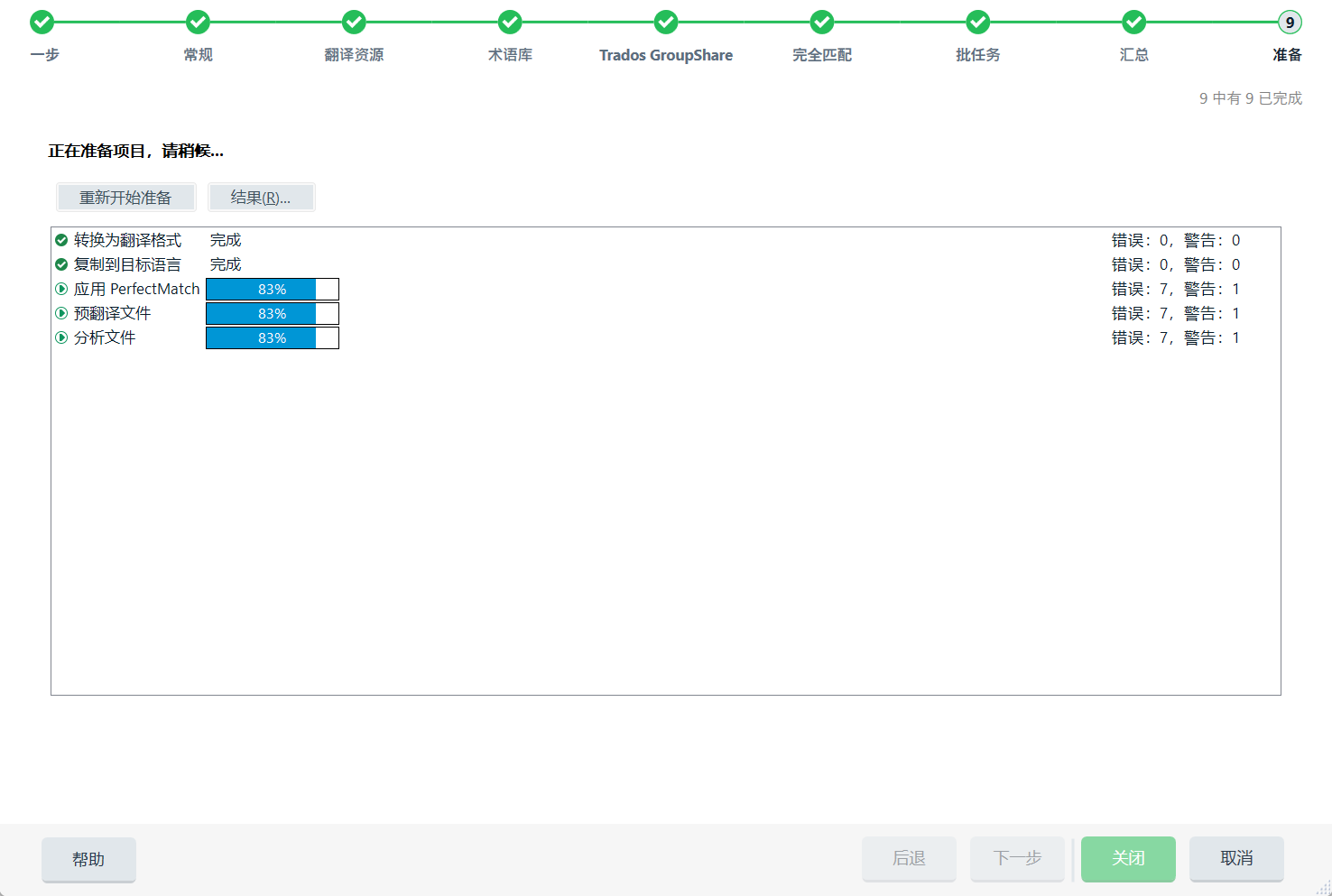
在后三个任务完成时若提示错误,可直接忽略错误,让项目创建完成。在项目创建成功后,再单独执行后面3个任务,包括预翻译、分析文件字数等。
项目创建完成之后,在执行预翻译任务时,你会发现依然有些文件无法正常执行预翻译,Trados程序可能会直接卡死!原因可能是文件太大,或者文件当中包含的Tag太多,Trados无法调用足够多的内存。
为了快速执行预翻译,找出存在问题的文件。我们可以一次性选定多个文件执行预翻译,当提示错误时,我们再找到有问题的文件,将它删除掉,随后我们转到原始文件夹,将对应的文件单独找出来处理。
这期间发现有问题的文件,连同我们早前创建项目过程中,无法生成sdlxliff文件的对应原始文件,可以一起将它们按照原始文件的层级整理在一起,集中进行处理。
记住使用我们的Project Console可直接生成原始文件项目的报告,包括文件总数、文件名、文件路径、文件大小等,这样可以更加明晰地辅助我们查找和归类文件。
对于导致内存不足的,那些超大的单个文件,可将它们分割成多个小文件。
对于异常的文件,使用我们的标记消除器处理一遍,往往就可以使用Trados正常处理了,并且文件处理之后,Tag明显大幅减少。
对于文件名包含特殊字符的,去掉文件名中的特殊字符。
对于文件很小,实质不包含内容的空文件,可以直接删除。
根据我们上述踩坑过程,我们要尽量将任务进行拆分。Trados的每个单项任务、预翻译、分析文件字数,都特别耗费时间。所以在准备超大型项目时,要预计2到3天的时间。同样的后期导出译文时,也要留足充足的时间。
锁重/去重
使用排重工具的目的是为了保证翻译的一致性,避免同样的句子,出现多种不同的翻译形式。
只要项目创建好,使用排重工具Toolbox可以在短短一分钟内锁定重复内容。
为什么排重工具Toolbox可以这么快,而Trados执行任务那么慢?
其中一个重要原因是排重工具Toolbox为64位程序,64位应用程序的内存占用几乎是无限的。
对此,我们可将排重工具Toolbox默认调用的内存调大。对于这一超大型项目,我们将内存设为调用4G内存即可。
如下图所示,红色部分对应的是内存调用。
-vmargs
-Dfile.encoding=UTF-8
-Xms8192m
-Xmx8192m
-XX:PermSize=96m
-XX:MaxPermSize=96m
-Xmn256m
另外,对于不便使用Trados程序的译员,我们同样地使用排重工具Toolbox一键导出为双语Word文件。Toolbox导出双语Word能在2分钟左右内完成,即使项目如此庞大。
术语提取
提取术语,目的也是保证术语翻译的一致性。
现有的各类工具(相关术语提取平台、人工智能平台)都不能支持超大/超多的文件和字数。
上传超大超多的文件,术语工具指定会崩溃。
我们必须压缩项目字数。
想到一个可以减少字数的方法,项目虽然大,但是包含大量的重复,我们可以通过剔除重复内容,仅保留新内容,这样可以有效减少字数,仅让术语工具/平台处理这些无重复的内容。
使用我们的排重工具Toolbox分批次加载锁重的sdlxliff文件,然后将加载的sdlxliff文件合并导出为一个不包含重复的Word文件。
注意排重工具Toolbox,虽然可以一次性将整个乃至多个项目的sdlxliff文件导出为一个Word文件,但是这样的Word文件会很大,光打开文件都很耗费时间。所以我们得分多个批次,将锁重的sdlxliff文件导出为Word文件。
为了提高术语工具的效率,还可将该Word文件另存为Unicode编码的纯文本文件。
术语提取完成后,我们使用术语管理工具汇总术语表,然后一键删除重复术语。
接着使用Glossary Converter一键将Excel表转为文件型术语库。
也可使用MultiTerm创建Trados GroupShare云端术语库,并将所有用户指定为“专家”,这样所有人员都可实时更新术语库,一个人更新的术语,所有人都能实时参考。
共享协作
为了保证翻译一致性,大幅提升效率,推荐采用本地Trados翻译 + 云端库,即本地Trados+连接GroupShare云端库。
在GroupShare云端上做翻译,那将是灾难。使用纯云端翻译,会有太多的问题。仅举一例,翻译过程中,可能会时不时统改术语。如何一次性打开很多文件?
Trados桌面程序虽然在项目准备阶段比较低效,但是在翻译工作上,是比在云端上翻译高效很多。
此外,翻译员还可以使用自己的“独门绝技”,包括自己的记忆库、特定的机器翻译等等,同时也能高效查询云端GroupShare上的记忆库。
使用GroupShare云端库,库的访问速度会受到服务器配置、带宽、访问人数等等因素影响。
为了最大限度地加快访问速度,可连接在GroupShare上新建的空库,而在本地使用积累很多年的文件型记忆库。
为了避免公司资产流失,文件型记忆库进行加密,再外发给合作译员。
机器翻译
我们可使用商业机器翻译,或国内定制化的机器翻译。
“专用的医学机器翻译模型,这使我们在后来的翻译过程中节省了大量的时间;同时又很好地解决了大批量文件需要多人协作翻译时的用词一致性问题,让译文无论是效率上还是质量上都得到巨大的提升。”
这些平台都支持Trados。可以直接将机器翻译插件发给译员,让译员自行安装。
在Trados的插件中,填入对应的密钥,即可实时获取机器译文。
质量检查
完成翻译后,必须进行QA。
由于项目庞大,忌讳将全部QA任务留到最后审校环节。
我们要在翻译步骤执行QA,在审校步骤执行QA。
这样在不同的环节都执行QA,相当于均衡地分配了QA工作量,会极大的减轻审校步骤的工作量。
在QA工具使用方面,可采用“Trados内置的QA工具与Xbench双重质检的方式”,或使用Qadistiller/Verfica +Xbench。
“用两种工具互查,确保最大程度地检出低错并修正”,也就是必须Double Check,确保没有遗漏的错误。
排版
译稿排版时,需对照原始文件,紧紧跟随原文的排版格式。
“创新性地利用PDF比较工具,将排版出的Word文件转为PDF文件,与原始PDF文件页页比对,以字符为单位核查排版偏差,方便人工纠正”。
参考和引用内容
医学翻译的技术应用创新——以某CTD翻译项目的临床部分阐释如何应对海量资料的翻译挑战
专访康茂峰科技创始人樊为国:企业的成长,在于不断地学习新技术