
翻译公司常碰见的Office系列文件包括Word、Excel和Powerpoint等。在使用诸如SDL Trados、Dejavu和MemoQ之类的CAT处理它们时,往往会碰到标记非常多的情况。对此,该如何办呢?
Excel文件
一般的“普通”的Excel文件,在使用CAT翻译(转换)时,是没有任何标记的。翻译公司无论是排重还是派稿,都很方便,不用担心标记问题。但是,我们可能偶尔会碰到Excel文件转换后,出现很多标记的情况,如下图。
转换前

转换后(Trados中)

碰到这样的情况,该怎么解决呢?您可以尝试将当前文件转为高版本或低版本。如果不奏效,您可以选定所有内容,将文字字体设为Arial Unicode MS。如果您的系统上没有此字体,可以点击此处下载。
要安装Arial Unicode MS字体,您可以将所下载的字体直接拷贝到C:\Windows\Fonts下,系统会自动安装。
还有一种情况是,即使采用了上述方法,标记也无法消除,其中的原因可能是生成Excel文件的软件的不正确行为导致。这种情况解决起来比较复杂,目前还无相关的解决方案。
Word文件
绝大多数情况下,在使用CAT翻译Word之前,可使用我们的标记消除器处理文件,这样可以大幅减少乃至彻底去掉所有标记。
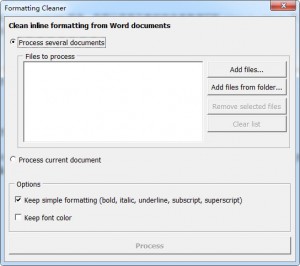
但是在少数情况下,即使清理文件之后,CAT工具中仍然存在很多标记。其中的原因和CAT的解析器有很大关系。例如,SDL Trados。
SDL Trados 在解析Word文件时,实际上处理的是底层的XML。SDL Trados 2014(及早期版本)和SDL Trados 2015在解析该XML文件时,2015更加智能,因此能有效减少导入Word文件时产生的标记。例如,在下例中,SDL Trados 2014只会查看”run properties” (w:rPr)标记是否包含和前一”run properties”相同的属性,如果没有,则会插入标记。而SDL Trados 2015则更加“聪明”,会忽略w:hint属性中的差异。
<w:r w:rsidRPr=”00B43639″>
<w:rPr>
<w:rFonts w:ascii=”宋体” w:hAnsi=”宋体” w:cs=”Arial” w:hint=”eastAsia”/>
<w:caps/>
</w:rPr>
<w:t>”输入框内输入</w:t>
</w:r>
对此,我们可以使用更高和更新版本的CAT,以免大量标记产生。
PowerPoint文件
PowerPoint在翻译之前,建议人工检查下是否存在断行的情况,如果有很多中间断开的短语/句子,在CAT中,同样该短语或句子也会断开,并可能生成更多标记。
另外,若PowerPoint在CAT中标记很多,可转换PowerPoint的版本,例如,将高版本转为低版本。这种方法往往有奇效。
总结
除了上述方法和诀窍外,您还可以在locren.com上搜索Word、Excel等关键字查看更多的Office文件处理技巧。
另外,我们的标记清除器日前已发布了最新版本。该版本进行了进一步改进,解决了少数文件处理速度慢的问题。现在,在绝大不多情侣下,都可以极速大批量处理Word文件。